Token To Word Calculator - Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Tokens are pieces of words that the openai language models breaks words down into. This is a simple calculator created to help you estimate the number of tokens based on the known number of words you expect to feed into gpt. Web tokens = tokenizer.encode(text) # calculate the number of tokens num_tokens = len(tokens.ids) print(number of tokens:, num_tokens) example of token calculator. Simply paste in the text you want to tokenize and it will calculate the number of tokens in the text. That way, you'll know whether your over the limit. It's important to note that the exact tokenization process varies between models. Please note that the exact tokenization process varies between models. A token calculator would identify “chatbots”, “are”, and “innovative” as individual words. Web to further explore tokenization, you can use our interactive tokenizer tool, which allows you to calculate the number of tokens and see how text is broken into tokens.

Calculator Word Image & Photo (Free Trial) Bigstock
Web tokens = tokenizer.encode(text) # calculate the number of tokens num_tokens = len(tokens.ids) print(number of tokens:, num_tokens) example of token calculator. Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Web use the tool provided below to.

Share mã nguồn tool get token full quyền (autoit) by nghiahsgs Mình
Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Simply paste in the text you want to tokenize and it will calculate the number of tokens in the text. Tokens are pieces of words that the openai.

Java Calculator by Samuel on Dribbble
Those token pieces are then fed into the model for it to run analyses, and provide a response. Replace this with your text to see how tokenization works. Simply paste in the text you want to tokenize and it will calculate the number of tokens in the text. Web to further explore tokenization, you can use our interactive tokenizer tool,.

How to Add a Calculator to Microsoft Word hiTechMV
It's important to note that the exact tokenization process varies between models. Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Please note that the exact tokenization process varies between models. A token calculator would identify “chatbots”,.

ZESA Token Viewer & Units Calculator
Web to further explore tokenization, you can use our interactive tokenizer tool, which allows you to calculate the number of tokens and see how text is broken into tokens. It's important to note that the exact tokenization process varies between models. A token calculator would identify “chatbots”, “are”, and “innovative” as individual words. Web tokens = tokenizer.encode(text) # calculate the.

How to Add a Calculator to Microsoft Word hiTechMV
A token calculator would identify “chatbots”, “are”, and “innovative” as individual words. That way, you'll know whether your over the limit. Web tokens = tokenizer.encode(text) # calculate the number of tokens num_tokens = len(tokens.ids) print(number of tokens:, num_tokens) example of token calculator. Web you can use the tool below to understand how a piece of text might be tokenized by.

Word Calculator Preview YouTube
Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Web use the tool provided below to explore how a specific piece of text would be tokenized and the overall count of words, characters and tokens. Tokens are.

Learn New Things How to Add Calculator for MS Word (Do Calculation in
Please note that the exact tokenization process varies between models. That way, you'll know whether your over the limit. This is a simple calculator created to help you estimate the number of tokens based on the known number of words you expect to feed into gpt. Tokens are pieces of words that the openai language models breaks words down into..

token word YouTube
Simply paste in the text you want to tokenize and it will calculate the number of tokens in the text. A token calculator would identify “chatbots”, “are”, and “innovative” as individual words. Tokens are pieces of words that the openai language models breaks words down into. This is a simple calculator created to help you estimate the number of tokens.
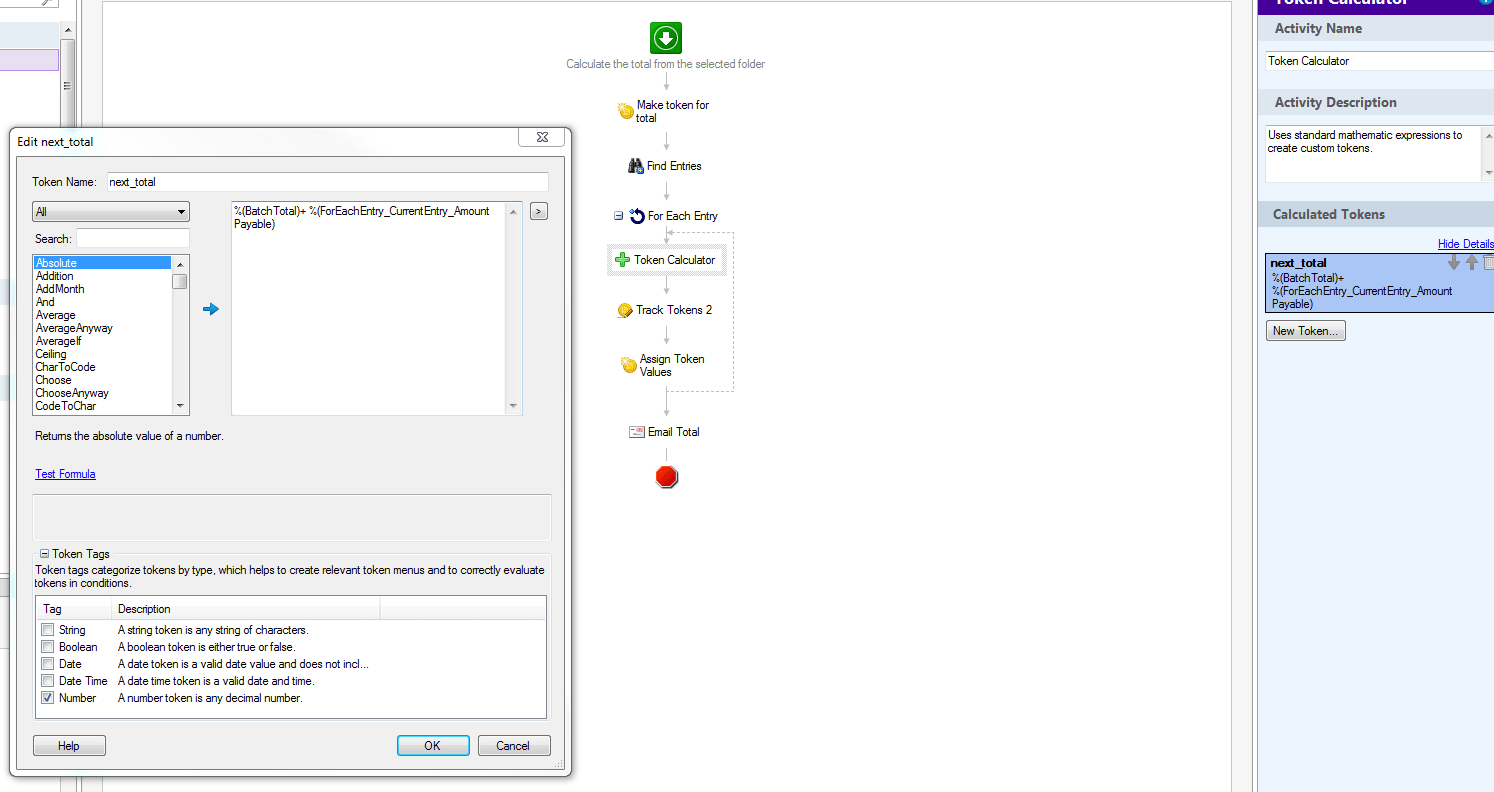
Using token calculator to Add ForEach entry to total token Laserfiche
It's important to note that the exact tokenization process varies between models. This is a simple calculator created to help you estimate the number of tokens based on the known number of words you expect to feed into gpt. That way, you'll know whether your over the limit. Please note that the exact tokenization process varies between models. Replace this.
Web you can use the tool below to understand how a piece of text might be tokenized by a language model, and the total count of tokens in that piece of text. Replace this with your text to see how tokenization works. This is a simple calculator created to help you estimate the number of tokens based on the known number of words you expect to feed into gpt. Simply paste in the text you want to tokenize and it will calculate the number of tokens in the text. Web use the tool provided below to explore how a specific piece of text would be tokenized and the overall count of words, characters and tokens. A token calculator would identify “chatbots”, “are”, and “innovative” as individual words. Please note that the exact tokenization process varies between models. Web to further explore tokenization, you can use our interactive tokenizer tool, which allows you to calculate the number of tokens and see how text is broken into tokens. Those token pieces are then fed into the model for it to run analyses, and provide a response. That way, you'll know whether your over the limit. Web tokens = tokenizer.encode(text) # calculate the number of tokens num_tokens = len(tokens.ids) print(number of tokens:, num_tokens) example of token calculator. It's important to note that the exact tokenization process varies between models. Tokens are pieces of words that the openai language models breaks words down into.